Beyond spaghetti: other motion tests
Video generators, audio systems, and coding models can all look convincing briefly. These tests examine whether motion stays coherent when physics, timing, and interaction matter.
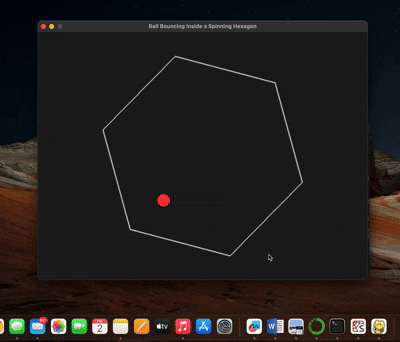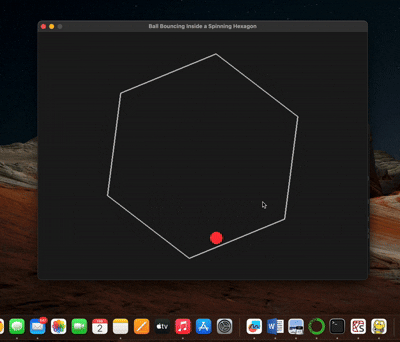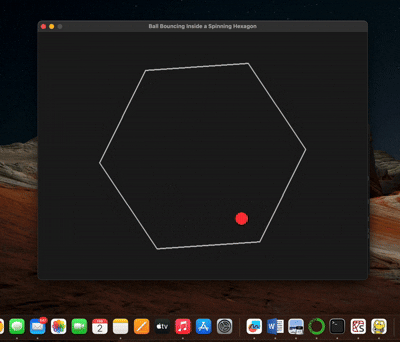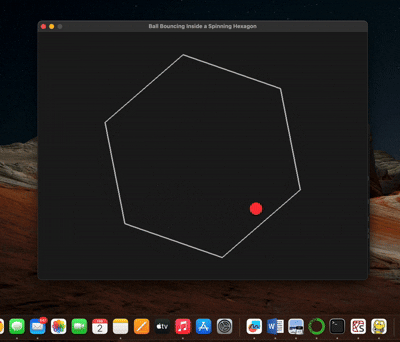
⬢ The Rotating Hexagon Test
The prompt sounds simple: draw a rotating hexagon, place a ball inside it, and make the ball respond to gravity, friction, and the walls. It is a popular informal test because one small animation exercises geometry, animation, and debugging at the same time.
Where it came from: bouncing-ball simulations are a classic programming exercise. This spinning-hexagon version was posted by developer Flavio Adamo on January 31, 2025 as a comparison between AI coding models.
Why it is complicated: the wall is moving while the ball collides with it. Correct code must find the nearest edge, resolve penetration, calculate the wall's local velocity from the hexagon's rotation, and reflect the ball relative to that moving surface. Corners, high speeds, and varying frame rates can produce tunneling, jitter, energy gain, or a ball that escapes.
🎥 Physics Violations
Generated videos still routinely break basic physics: liquid ignoring gravity, solid objects clipping through each other, cloth that doesn't drape properly. These are hard to detect in still frames but obvious in motion.
👤 Identity Preservation
Early video models often changed facial identity across frames. Temporal consistency has improved substantially since 2024, but profile turns and quick movements can still cause drift.
🎤 Audio-Visual Sync
Until 2025, most AI video had no audio at all. Veo 3 introduced native audio generation, but sync remains imperfect (the infamous "crunchy spaghetti" sound). Lip sync during speech is advancing fast but still detectable as uncanny in most cases.
📸 Background Character Behavior
While main subjects can look convincing in short clips, background characters may loop, freeze, or perform inconsistent actions. This makes background motion a useful repeatability test.
🎧 Noisy-Scene Reasoning
Audio models can transcribe clean speech well, yet higher-order reasoning can collapse when speech overlaps with laughter, weather, music, or classroom noise. RSA-Bench was introduced in January 2026 to test this gap.
🎙 Voice-Cloning Robustness
Change the microphone, language, reference noise, speaking length, or compression and voice similarity can degrade sharply. RVCBench evaluates these real-world shifts across the generation pipeline.